Canister development security best practices
This document contains canister development best practices for both Motoko and Rust.
Smart Contracts Canister Control
Use a decentralized governance system like SNS to make a canister have a decentralized controller
Security Concern
The controller of a canister can change / update the canister whenever they like. If a canister e.g. stores assets such as ICP, this effectively means that the controller can steal these by updating the canister and transfer the cycles to their account.
Recommendation
- Consider passing canister control to a decentralized governance system such as the Internet Computer's Service Nervous System (SNS), so that changes to the canister are only executed if the SNS community approves them collectively through voting. If an SNS is used, use an SNS on the SNS subnet as this guarantees that the SNS is running an NNS-blessed version and maintained as part of the IC. These SNSs will be available soon. See the roadmap here and the design proposal here
- Another option would be to create an immutable canister smart contract by removing the canister controller completely. However, note that this implies that the canister cannot be upgraded, which may have severe implications in case e.g. a bug were found. The option to use a decentralized governance system and thus being able to upgrade smart contracts is a big advantage of the Internet Computer ecosystem compared to other blockchains. ** Note that, contrary to some other blockchains, also immutable smart contracts need cycles to run, and they can receive cycles.
- It is also possible to implement a DAO Decentralized Autonomous Organization on the IC from scratch. If you decide to do this (e.g. along the lines of the basic DAO example), be aware that this is security critical and must be security reviewed carefully. Furthermore, users will need to verify that the DAO is controlled by itself.
Verify the ownership of smart contracts you depend on
Security Concern
If a canister depends on another canister smart contract (i.e. makes inter-canister calls to it), it is essential that the canister smart contract that one depends on is owned by a decentralized governance system. Otherwise, i.e. if it has a controller, they could modify the smart contract without others noticing, e.g. to steal assets held by the canister.
Recommendation
If you interact with a canister that you require to be decentralized, make sure it is controlled by the NNS, a service nervous system (SNS) or a decentralized governance system, and review under what conditions and by whom the smart contract can be changed.
Authentication
Make sure any action that only a specific user should be able to do requires authentication
Security Concern
If this is not the case, an attacker may be able to perform sensitive actions on behalf of a user, compromising their account.
Recommendation
- By design, for every canister call the caller can be identified. The calling principal can be accessed using the system API’s methods
ic0.msg_caller_sizeandic0.msg_caller_copy(see here). If e.g. Internet Identity is used, the principal is the user identity for this specific origin, see here. If some actions (e.g. access to user’s account data or account specific operations) should be restricted to a principal or a set of principals, then this must be explicitly checked in the canister call, for example as follows in Rust:
// Let pk be the public key of a principal that is allowed to perform
// this operation. This pk could be stored in the canister's state.
if caller() != Principal::self_authenticating(pk) { ic_cdk::trap(...) }
// Alternatively, if the canister keeps data for different principals
// in e.g. a map such as BTreeMap<Principal, UserData>, then the canister
// must ensure that each caller can only access and perform operations
// on their own data:
if let Some(user_data) = user_data_store.get_mut(&caller()) {
// perform operations on the user's data
}
In Rust, the
ic_cdkcrate can be used to authenticate the caller usingic_cdk::api::caller. Make sure the returned principal is of typePrincipal::self_authenticatingand identify the user’s account using the public key of that principal, see the example code above.Do authentication as early as possible in the call to avoid unauthenticated actions and potentially expensive operations before authentication. It is also a good idea to deny service to anonymous users.
Disallow the anonymous principal in authenticated calls
Security Concern
The caller from the system API (e.g. ic0::api::caller in Rust) may also return Principal::anonymous(). In authenticated calls, this is probably undesired (and could have security implications) since this would behave like a shared account for anyone that does unauthenticated calls.
Recommendation
In authenticated calls, make sure the caller is not anonymous and return an error or trap if it is. This could e.g. be done centrally by using a helper method. In Rust it could e.g. look as follows:
fn caller() -> Result<Principal, String> {
let caller = ic0::api::caller();
// The anonymous principal is not allowed to interact with canister.
if caller == Principal::anonymous() {
Err(String::from(
"Anonymous principal not allowed to make calls.",
))
} else {
Ok(caller)
}
}
Asset Certification
Use HTTP asset certification and avoid serving your dApp through raw.icp0.io
Security Concern
Dapps on the IC can use asset certification to make sure the HTTP assets delivered to the browser are authentic (i.e. threshold-signed by the subnet). If an app does not do asset certification, it can only be served insecurely through raw.icp0.io , where no asset certification is checked. This is insecure since a single malicious node or boundary node can freely modify the assets delivered to the browser.
If an app is served through raw.icp0.io in addition to icp0.io, an adversary may trick users (phishing) into using the insecure raw.icp0.io.
Recommendation
Only serve assets through
<canister-id>.icp0.iowhere the service worker verifies asset certification. Do not serve through<canister-id>.raw.icp0.io.Serve assets using the asset canister (which creates asset certification automatically), or add the
ic-certificateheader including the asset certification as e.g. done in the NNS dApp or Internet Identity.Check in the canister’s
http_requestmethod if the request came through raw. If so, return an error and do not serve any assets.
Canister Storage
Rust: Use thread_local! with Cell/RefCell for state variables and put all your globals in one basket.
Security Concern
Canisters need global mutable state. In Rust, there are several ways to achieve this. However, some options can lead e.g. to memory corruption.
Recommendation
Use
thread_local!withCell/RefCellfor state variables. (from Effective Rust Canisters)Put all your globals in one basket. (from Effective Rust Canisters)
Limit the amount of data that can be stored in a canister per user
Security Concern
If a user is able to store a big amount of data on a canister, this may be abused to fill up the canister storage and make the canister unusable.
Recommendation
Limit the amount of data that can be stored in a canister per user. This limit has to be checked whenever data is stored for a user in an update call.
Consider using stable memory, version it, test it
Security Concern
Canister memory is not persisted across upgrades. If data needs to be kept across upgrades, a natural thing to do is to serialize the canister memory in pre_upgrade, and deserialize it in post_upgrade. However, the available number of instructions for these methods is limited. If the memory grows too big, the canister can no longer be updated.
Recommendation
Stable memory is persisted across upgrades and can be used to address this issue.
Consider using stable memory. (from Effective Rust Canisters). See also the disadvantages discussed there.
See also the section on upgrades in How to audit an Internet Computer canister (though focused on Motoko)
Write tests for stable memory to avoid bugs.
Some libraries (mostly work in progress / partly unfinished) that people work on:
https://github.com/dfinity/stable-structures/
- HashMap: https://github.com/dfinity/stable-structures/pull/1 (currently not prod ready)
See Current limitations of the Internet Computer, sections "Long running upgrades" and "[de]serialiser requiring additional wasm memory"
For example, internet identity uses stable memory directly to store user data.
Consider encrypting sensitive data on canisters
Security Concern
By default, canisters provide integrity but not confidentiality. Data stored on canisters can be read by nodes / replicas.
Recommendation
Consider end-to-end encrypting any private or personal data (e.g. user’s personal or private information) on canisters.
The example dApp Encrypted Notes illustrates how end-to-end encryption can be done.
Create backups
Security Concern
A canister could be rendered unusable so it could never be upgraded again e.g. due to the following reasons:
It has a faulty upgrade process (due to some bug from the dapp developer).
The state becomes inconsistent / corrupt because of a bug in the code that persists data.
Recommendation
Make sure methods used in upgrading are tested or the canister becomes immutable.
It may be useful to have a disaster recovery strategy that makes it possible to reinstall the canister.
See the "Backup and recovery" section in How to audit an Internet Computer canister
Inter-Canister Calls and Rollbacks
Message Execution Basics
To understand the issues around async inter-canister calls, one needs to understand a few properties about message execution. This is also explained in the community conversation on Security Best Practices.
We fist provide a few definitions. A call is a canister's implementation of either an update or query call that it exposes. For example, if the Rust CDK is used, these are usually annotated with #[query] or #[update], respectively. A message is a set of consecutive instructions that a subnet executes for a canister. We'll see in the following that a call can be split into several messages if inter-canister calls are made. The following properties are essential:
Property 1: Only a single message is processed at a time per canister. So message execution is sequential, and never parallel.
Property 2: Each call (query / update) triggers a message. When an inter-canister call is made using await, the code after the call (the callback, highlighted in blue) is executed as a separate message.
Note that if the code does not await the response, the code after the callback (until the next inter-canister call is triggered using await) is executed in the same message.
For example, consider the following Motoko code:

The first message that is executed here are lines 2-3, until the inter-canister call is made using the await syntax (orange box). The second message executes lines 3-5: when the inter-canister call returns (blue box). We call this part the callback of the inter-canister call. The two messages involved in this example will always be scheduled sequentially.
Property 3: Successfully delivered requests are received in the order in which they were sent. In particular, if a canister A sends m1 and m2 to canister B in that order, then, if both are accepted, m1 is executed before m2.
Note that this property only gives a guarantee on when the messages are executed, but there is no guarantee on the ordering of the responses received.
Property 4: Messages from interleaving calls have no reliable execution ordering.
Property 3 provides a guarantee on the execution order of messages on a target canister. However, if multiple calls interleave, one cannot assume additional ordering guarantees for these interleaving calls. To illustrate this, let's consider the above example code again, and assume the method example is called twice in parallel, the resulting calls being Call 1 and Call 2. The following illustration shows two possible message orderings. On the left, the first call's messages are scheduled first, and only then the second call's messages are executed. On the right, we see another possible message scheduling, where the first messages of each call are executed first. Your code should result in a correct state regardless of the message ordering.
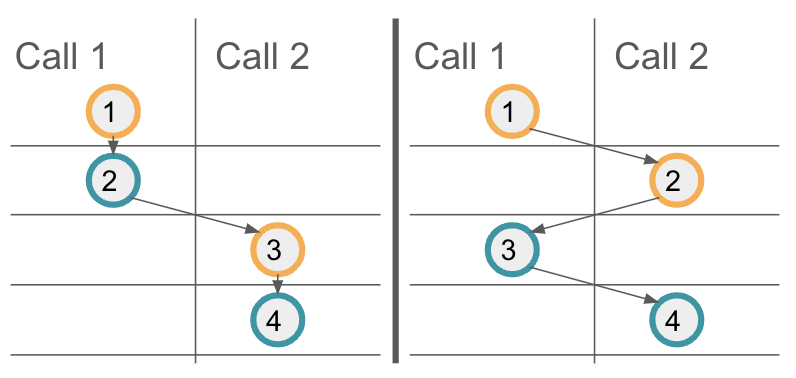
Property 5: On a trap / panic, modifications to the canister state for the current message are not applied.
For example, if a trap in the second message (blue box) of the above example occurs, canister state changes resulting from that message, even earlier in the blue box, are discarded. However, note that any state changes from earlier messages and in particular the first message (orange box) have been applied, as that message executed successfully.
Property 6: Inter-canister messaging is not reliable.
Every inter-canister call is guaranteed to receive a response, either from the canister, or synthetically produced by the protocol. However, the response does not have to be successful, but can also be a reject response. The reject may come from the called canister, but it may also be generated by the Internet Computer. Such system-generated rejects can occur at any time, and cannot be controlled by canister authors. Thus, it's important that the calling canister handles reject responses as well. Note that a reject response generally guarantees that the message had not been processed successfully by the called canister.
For more details, refer to the Interface Specification section on ordering guarantees and the section on abstract behaviour which defines message execution in more detail.
Avoid traps after await
Security Concern
Traps / panics roll back the canister state, as described in Property 5 above. So any state change followed by a trap or panic can be risky. This is also an important concern when inter-canister calls are made. If a panic/trap occurs after an await to an inter-canister call, then the state is reverted to the snapshot before the inter-canister call callback invocation, and not before the entire call!
This may e.g. lead to the following issues:
Suppose some state changes are applied and then an inter-canister call is issued. Also, assume that these state changes leave the canister in an inconsistent state, and that state is only made consistent again in the callback. Now if there is a trap in the callback, this leaves the canister in an inconsistent state.
A concrete bug of this kind is the following. Assume an inter-canister call is issued to transfer funds. In the callback, the canister accounts for having made that transfer by reflecting that fact in the canister storage. However, suppose the callback also updates some usage statistics data, which eventually leads to a trap when some data structure becomes full. As soon as that is the case, the canister ends up in an inconsistent state because the state changes in the callback are no longer applied and thus the transfers are not correctly accounted for.
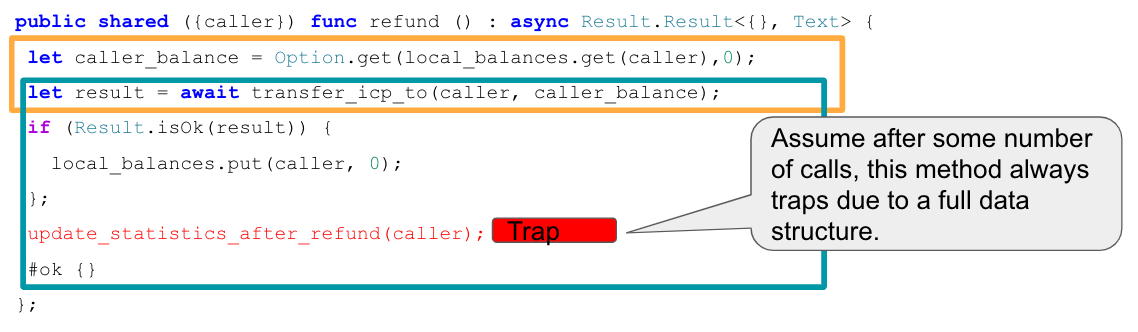 This example is also discussed in this community conversation.
This example is also discussed in this community conversation.Another example: if e.g. part of the canister state is locked before an inter-canister call and released in the callback, the lock may never be released if the callback traps.
Generally, there can be bugs where data is not persisted when the developer expected it to be.
Note that in Rust, from Rust CDK version 0.5.1, any local variables still go out of scope on trap. The CDK actually calls into the ic0.call_on_cleanup API to release these resources. This helps to prevent some of the above issues, as e.g. it is possible to use Rust's Drop implementation to release locked resources, as we discuss in "Be aware that there is no reliable message ordering"
Recommendation
Watch the community conversation on Security Best Practices which shows a concrete example of an issue as described here.
Don’t lock shared resources across await boundaries (from Effective Rust Canisters)
For context: IC interface spec on message execution
See also: "Inter-canister calls" section in How to audit an Internet Computer canister
Be aware that there is no reliable message ordering
Security Concern
As described in the Message Execution Basics above, messages (but not entire calls) are processed atomically. In particular, as described in Property 4 above, messages from interleaving calls do not have a reliable execution ordering. Thus, the state of the canister (and other canisters) may change between the time an inter-canister call is started and the time when it returns, which may lead to issues if not handled correctly. These issues are generally called 'Reentrancy bugs' (see e.g. the Ethereum Best Practices on Reentrancy). Note however that the messaging guarantees (and thus the bugs) on the Internet Computer are different from Ethereum.
We provide two concrete and somewhat similar types of bugs to illustrate potential reentrancy security issues:
Time-of-check time-of-use issues. These occur when some condition on global state is checked before an inter-canister call, and then wrongly assuming the condition still holds when the call returns. For example, one might check if there is sufficient balance on some account, then issue an inter-canister call and finally make a transfer as part of the callback message. When the second inter-canister call starts, it is possible that the condition which was checked initially no longer holds, because other ledger transfers may have happened before the callback of the first call is executed (see also Property 4 above).
Double-Spending issues. Such issues occur when a transfer is issued twice, often because of unfavorable message scheduling. For example, suppose we check if a caller is eligible for a refund and if so, transfer some refund amount to them. When the refund ledger call returns successfully, we set a flag in the canister storage indicating that the caller has been refunded. This is vulnerable to double-spending because the refund method can be called twice by the caller in parallel, in which case it is possible that the messages before issuing the transfer (including the eligibility check) are scheduled before both callbacks. A detailed explanation of this issue can be found in the Community Conversation on Security Best Practices.
Recommendation
We highly recommend to carefully review any canister code that makes async inter-canister calls (await). If two messages access (read or write) the same state, review if there is a possible scheduling of these messages that leads to illegal transactions or inconsistent state.
See also: "Inter-canister calls" section in How to audit an Internet Computer canister
To address issues around message ordering that can lead to bugs, one usually employs locking mechanisms to ensure that e.g. a caller (or anyone) can only execute an entire call (which involves several messages) once at a time. A simple example is also given in the community conversation mentioned above.
The locks would usually be released in the callback. That bears the risk that the lock may never be released in case the callback traps, as we discussed in Avoid Traps after await. In Rust, there is a nice pattern to avoid this issue by using Rust's Drop implementation. The example code below shows how one can implement a lock per caller (CallerGuard) with a Drop implementation. From Rust CDK version 0.5.1, any local variables still go out of scope if the callback traps, so the lock on the caller is released even in that case.
pub struct State {
pending_requests: BTreeSet<Principal>,
}
thread_local! {
static STATE: RefCell<State> = RefCell::new(State{pending_requests: BTreeSet::new()});
}
pub struct CallerGuard {
principal: Principal,
}
impl CallerGuard {
pub fn new(principal: Principal) -> Result<Self, String> {
STATE.with(|state| {
let pending_requests = &mut state.borrow_mut().pending_requests;
if pending_requests.contains(&principal){
return Err(format!("Already processing a request for principal {:?}", &principal));
}
pending_requests.insert(principal);
Ok(Self { principal })
})
}
}
impl Drop for CallerGuard {
fn drop(&mut self) {
STATE.with(|state| {
state.borrow_mut().pending_requests.remove(&self.principal);
})
}
}
#[update]
#[candid_method(update)]
async fn example_call_with_locking_per_caller() -> Result<(), String> {
let caller = ic_cdk::caller();
// using `?`, we return an error immediately if there is already a call in progress for `caller`.
let _ = CallerGuard::new(caller)?;
// do anything, call other canisters
Ok(())
} // here the guard goes out of scope and is dropped
mod test {
use super::*;
#[test]
fn should_obtain_guard_for_different_principals() {
let principal_1 = Principal::anonymous();
let principal_2 = Principal::management_canister();
let caller_guard = CallerGuard::new(principal_1);
assert!(caller_guard.is_ok());
assert!(CallerGuard::new(principal_2).is_ok());
}
#[test]
fn should_not_obtain_guard_twice_for_same_principal() {
let principal = Principal::anonymous();
let caller_guard = CallerGuard::new(principal);
assert!(caller_guard.is_ok());
assert!(CallerGuard::new(principal).is_err());
}
#[test]
fn should_release_guard_on_drop() {
let principal = Principal::anonymous();
{
let caller_guard = CallerGuard::new(principal);
assert!(caller_guard.is_ok());
} // drop caller_guard as it goes out of scope here
// it is possible to get a guard again:
assert!(CallerGuard::new(principal).is_ok());
}
}
This pattern can be extended e.g. to work for the following use cases:
- A global lock that does not only lock per caller. For this, set a boolean flag in the canister state instead of using a
BTreeSet<Principal>. - A guard that makes sure that only a limited number of principals are allowed to execute a method at the same time. For this, one can return an error in
CallerGuard::new()in casepending_requests.len() >= MAX_NUM_CONCURRENT_REQUESTS. - A guard that limits the number of times a method can be called in parallel. For this, use a counter in the canister state that is checked and increased in
CallerGuard::new()and decreased inDrop.
Finally, note that the same guard can be used in several methods to restrict parallel execution of them.
Handle rejected inter-canister calls correctly
Security Concern
As stated by the Property 6 above, inter-canister calls can fail in which case they result in a reject. See reject codes for more detail. The caller must correctly deal with the reject cases, as they can happen in normal operation, e.g. because of insufficient cycles on the sender or receiver side, or because some data structures (like message queues) are full.
Not handling the error cases correctly is risky: for example, if a ledger transfer results in an error, the callback dealing with that error must interpret it correctly (the transfer did not happen).
Recommendation
When making inter-canister calls, always handle the error cases (rejects) correctly. These errors imply that the message has not been successfully executed.
Only make inter-canister calls to trustworthy canisters
Security Concern
If inter-canister calls are made to potentially malicious canisters, this can lead to DoS issues or there could be issues related to candid decoding. Also, the data returned from a canister call could be assumed to be trustworthy when it is not.
If a canister is called with a callback, the receiver can stall indefinitely if the peer does not respond, resulting in DoS. A canister can no longer be upgraded if it is in that state. Recovery would involve reinstalling, wiping the state of the canister.
In summary, this can DoS a canister, consume an excessive amount of resources, or lead to logic bugs if the behavior of the canister depends on the inter-canister call response.
Recommendation
Only make inter-canister calls to trustworthy canisters.
Sanitize data returned from inter-canister calls.
See "Talking to malicious canisters" section in How to audit an Internet Computer canister
See Current limitations of the Internet Computer, section "Calling potentially malicious or buggy canisters can prevent canisters from upgrading"
Make sure there are no loops in call graphs
Security Concern
Loops in the call graph (e.g. canister A calling B, B calling C, C calling A) may lead to canister deadlocks.
Recommendation
Avoid such loops!
For more information, see Current limitations of the Internet Computer, section "Loops in call graphs"
Canister Upgrades
Be careful with panics during upgrades
Security Concern
If a canister traps or panics in pre_upgrade, this can lead to permanently blocking the canister, resulting in a situation where upgrades fail or are no longer possible at all.
Recommendation
Avoid panics / traps in
pre_upgradehooks, unless it is truly unrecoverable, so that any invalid state can fixed by upgrading. Panics in the pre-upgrade hook prevent upgrade, and since the pre-upgrade hook is controlled by the old code, it can permanently block upgrading.Panic in the
post_upgradehook if state is invalid, so that one can retry the upgrade and try to fix the invalid state. Panics in the the post-upgrade hook abort the upgrade, but one can retry with new code.See also the section on upgrades in How to audit an Internet Computer canister (though focused on Motoko)
See Current limitations of the Internet Computer, section "Bugs in
pre_upgradehooks"
Reinstantiate timers during upgrades
Security Concern
Global timers are deactivated upon changes to the canister's Wasm module. The IC specification states this as follows:
The timer is also deactivated upon changes to the canister's Wasm module (calling install_code, uninstall_code methods of the management canister or if the canister runs out of cycles). In particular, the function canister_global_timer won't be scheduled again unless the canister sets the global timer again (using the System API function ic0.global_timer_set).
Upgrade is a mode of install_code and hence the timers are deactivated during an upgrade.
This could result in a vulnerability in certain cases where security controls or other critical features rely on these timers to function. For example, a DEX which relies on timers to update the exchange rates of currencies could be vulnerable to arbitraging opportunities if the rates are no longer updated.
Since global timers are used internally by the Motoko Timer mechanism, the same holds true for Motoko Timer. As explained in the pull request under "The upgrade story", the global timer gets jettisoned on upgrade, and the timers need to be set up in the post-upgrade hook.
As explained in this pull request under "Opting out", the behavior is different when using Motoko and implementing system func timer. The timer function will be called after an upgrade. In case your canister was using timers for recurring tasks, the timer function would likely set the global timer again for a later time. However, the time between invocations of timer would not be consistent as the upgrade triggered an "unexpected" call to timer.
Using the rust CDK, the reccuring timer is also lost on upgrade as explained in the API documentation of set_timer_interval.
Recommendation
- Keep track of global timers in the
pre_upgradehook. Store any state in stable variables. - Set timers in the
post_upgradehook. - See the Motoko documentation on recurringTimer
- See the Rust documentation on set_timer_interval
Miscellaneous
Test your canister code even in presence of System API calls
Security Concern
Since canisters interact with the system API, it is harder to test the code because unit tests cannot call the system API. This may lead to lack of unit tests.
Recommendation
Create loosely coupled modules that do not depend on the system API and unit test those. See this recommendation (from Effective Rust Canisters).
For the parts that still interact with the system API: create a thin abstraction of the System API that is faked in unit tests. See the recommendation (from Effective Rust Canisters). For example, one can implement a ‘Runtime’ as follows and then use the ‘MockRuntime’ in tests (code by Dimitris Sarlis):
use ic_cdk::api::{
call::call, caller, data_certificate, id, print, time, trap,
};
#[async_trait]
pub trait Runtime {
fn caller(&self) -> Result<Principal, String>;
fn id(&self) -> Principal;
fn time(&self) -> u64;
fn trap(&self, message: &str) -> !;
fn print(&self, message: &str);
fn data_certificate(&self) -> Option<Vec<u8>>;
(...)
}
#[async_trait]
impl Runtime for RuntimeImpl {
fn caller(&self) -> Result<Principal, String> {
let caller = caller();
// The anonymous principal is not allowed to interact with the canister.
if caller == Principal::anonymous() {
Err(String::from(
"Anonymous principal not allowed to make calls.",
))
} else {
Ok(caller)
}
}
fn id(&self) -> Principal {
id()
}
fn time(&self) -> u64 {
time()
}
(...)
}
pub struct MockRuntime {
pub caller: Principal,
pub canister_id: Principal,
pub time: u64,
(...)
}
#[async_trait]
impl Runtime for MockRuntime {
fn caller(&self) -> Result<Principal, String> {
Ok(self.caller)
}
fn id(&self) -> Principal {
self.canister_id
}
fn time(&self) -> u64 {
self.time
}
(...)
}
Make canister builds reproducible
Security Concern
It should be possible to verify that a canister does what it claims to do. the IC provides a SHA256 hash of the deployed WASM module. In order for this to be useful, the canister build has to be reproducible.
Recommendation
Make canister builds reproducible. See this recommendation (from Effective Rust Canisters). See also Developer docs on this.
Expose metrics from your canister
Security Concern
In case of attacks, it is great to be able to obtain relevant metrics from canisters, such as number of accounts, size of internal data structures, stable memory, etc.
Recommendation
Expose metrics from your canister. (from Effective Rust Canisters)
Don’t rely on time being strictly monotonic
Security Concern
The time read from the System API is monotonic, but not strictly monotonic. Thus, two subsequent calls can return the same time, which could lead to security bugs when the time API is used.
Recommendation
See the "Time is not strictly monotonic" section in How to audit an Internet Computer canister
Protect against draining the cycles balance
Security Concern
Canisters pay for their cycles which makes them inherently vulnerable to attacks that consume all their cycles.
Recommendation
Consider monitoring, early authentication, rate limiting on canister level to mitigate this. Also, be aware that an attacker will aim for the call consuming most cycles. See the "Cycle balance drain attacks section" in How to audit an Internet Computer canister .
Nonspecific to the Internet Computer
The best practices in this section are very general and not specific to the Internet Computer. This list is by no means complete and only lists a few very specific concerns that have led to issues in the past.
Validate inputs
Security Concern
The data sent in query and update calls is generally untrusted. The message size limit is a few MB. This can e.g. lead the following issues:
If unvalidated data is rendered in web UIs or displayed in other systems, this can lead to injection attacks (e.g. XSS).
Messages of big size could be sent and potentially stored in the canister, consuming an excessive amount of storage.
Big inputs (e.g. big lists or strings) could trigger an excessive amount of computation, resulting in DoS and consuming many cycles. See also Protect against draining the cycles balance
Recommendation
Perform input validation, see e.g. the OWASP cheat sheet.
"Large data attacks" section in How to audit an Internet Computer canister (be aware of Candid space bombs)
ASVS 5.1.4: Verify that structured data is strongly typed and validated against a defined schema including allowed characters, length and pattern (e.g. credit card numbers or telephone, or validating that two related fields are reasonable, such as checking that suburb and zip/postcode match).
Rust: Don’t use unsafe Rust code
Security Concern
Unsafe Rust code is risky because it may introduce memory corruption issues.
Recommendation
Avoid unsafe code whenever possible.
See the Rust security guidelines
Consider the Dfinity Rust Guidelines.
Rust: Avoid integer overflows
Security Concern
Integers in Rust may overflow. While such overflows lead to panics in the debug configuration, the values are just wrapped around silently in release compilation. This can cause major security issues e.g. when the integers are used as indices, unique IDs, or if cycles or ICP amounts are computed.
Recommendation
Review your code carefully for any integer operations that may wrap around.
Use the
saturatedorcheckedvariants of these operations, such assaturated_add,saturated_sub,checked_add,checked_sub, etc. See e.g. the Rust docs foru32.See also the Rust security guidelines on integer overflows.
Rust: Avoid floating point arithmetic for financial information
Security Concern
Floats in Rust may behave unexpectedly. There can be undesirable loss of precision under certain circumstances. When dividing by zero, the result could be -inf, inf, or NaN. When converting to integer, this can lead to unexpected results. (There is no checked_div for floats.)
Recommendation
Use rust_decimal::Decimal or num_rational::Ratio. Decimal uses a fixed-point representation with base 10 denominators, and Ratio represents rational numbers. Both implement checked_div to handle division by zero, which is not available for floats. Numbers in common use like 0.1 and 0.2 can be represented more intuitively with Decimal, and can be represented exactly with Ratio. Rounding oddities like 0.1 + 0.2 != 0.3, which happen with floats in Rust, do not arise with Decimal (see https://0.30000000000000004.com/ ). With Ratio, the desired precision can be made explicit. With either Decimal or Ratio, although one still has to manage precision, the above make arithmetic easier to reason about.
For expensive calls, consider using captchas or proof of work
Security Concern
If an update or query call is expensive e.g. in terms of memory used or cycles consumed, this may make it easy for bots to render the canister unusable (e.g. by filling up it’s storage).
Recommendation
If the dApp offers such operations, consider bot prevention techniques such as adding Captchas or proof of work. There is e.g. a captcha implementation in internet identity.